A practical, no-BS guide based on real submissions, real rejections, and real lessons - not theory.
Who is this for?
If you are sitting there thinking “bug bounty is too hard” or “all the good bugs are already found” - this report is for you. I am going to share my actual journey. Not just the wins. The duplicates. The rejections. The informational closures. The emails where companies said “thanks but no thanks.” And then the $$$$ payouts, the private pentest invitations, and the moments where everything clicked.
This is not a tutorial. This is a story backed by data.
The Numbers (No Sugarcoating - From Sep 2025 - April 2026)
Let me start with the raw stats from my engagements:
Overall Portfolio
| Metric | Number |
|---|---|
| Total targets hunted | 45+ (including very small ones with 2/3 subdomains |
| Targets where I found something | 17 |
| Total findings reported | 40~ |
| Findings that were Critical | 9 |
| Findings that were High | 13 |
| Findings that were Medium | 6 |
| Findings that were Low/Info | 12 |
| Hypotheses I generated | 300+ |
| Chain exploits discovered | 6+ |
| Targets with zero findings | 28 |
| Duplicate reports received | Multiple |
| Reports rejected outright | Multiple |
| Reports marked Informative | Multiple |
Look at that. 28 targets with ZERO findings. More than half. That is the reality nobody talks about on Twitter.
Platform Breakdown
I have submitted across:
- HackerOne - main platform, 15+ reports (All duplicates)
- Bugcrowd - None
- bugbounty.ch - Swiss VDP programs - Just 1 program 1 report Medium
- Com Olho - Just 1 program 2 reports both duplicates
- Self-hosted programs - Biggest wins, all of my good payouts and HoFs are from here.
The Real Journey: From Zero to Here
Phase 1: The “Just Start” Phase (Early Days)
My first responsible disclosure was to a healthcare company in January 2026. I found vulnerabilities, reported them via email, and the response was:
“That’s very gracious of you, thank you so much for understanding.”
No bounty program. No payout. Just a LinkedIn connection request from the CTO and CEO.
But here is what happened next - They offered me a full time job (which I politely declined) and also asked me to be their dedicated pen tester on a retainer. I said “I have managed bug bounty programs for large firms throughout my career. Happy to do dedicated pen testing so you can save money before your actual program goes live.”
Lesson 1: Bug bounty is not just about finding bugs. It is about building relationships. Some engagements turn into paid pentest assignments.
That email from January 2026? It taught me that being professional, being transparent, and offering value - even when there is no bounty - opens doors you cannot imagine.
Phase 2: The Duplicate/Rejection Phase (The Grind)
On Com Olho and HackerOne platform, I submitted a total 20ish reports:
“All of them were marked as Duplicates.
How did that feel? Terrible. You spend hours finding something, writing the report, and someone either found it first or the program does not care.
Lesson 2: Duplicates and rejections are not failures. They are data points. A duplicate means your methodology WORKS - you found a real bug. You were just slower because you do full time job or have other repsonsibilities compared to other full time bug hunters. So don’t get discouraged, keep pushing!
Phase 3: The “$$$$ email” phase (It clicks)
Then came this email:
“Thank you for your submission regarding an issue with one of our internal API endpoints. We have completed our review and can confirm this is a valid security finding.”
Severity: High. Bounty: $$$$. Invoice attached.
What changed? Not my skills dramatically. What changed was my approach. I stopped running scanners and hoping. I started thinking like a developer. I started asking “what would go wrong if…?” instead of “what tool should I run?”
Phase 4: The Systematic Phase (Where I Am Now)
My current approach is hypothesis-driven hunting. Here is what it looks like with real numbers from one engagement:
Target: European Industrial Company (VDP)
- OSINT phase: 411 subdomains discovered, 28 vendors mapped, 25 employee credentials found in stealer databases
- Recon phase: 327 subdomains enumerated, 17 live hosts confirmed, 5 CDN providers mapped
- Front-analysis: 34 hosts visited, 39 endpoints inventoried, 6 new hostnames discovered via CSP headers
- Hypothesis generation: 110 hypotheses created (87 unauthenticated, 23 authenticated) - What the heck is hypothesis? Its there in the section below.
- Testing: 87 test cases tested from hypothesis.
- Results: 9 confirmed, 67 falsified, 11 needs manual verification
- Final findings: 7 validated (2 downgraded after knowing it does not affect company from impact standpoint)
That is a ~10% hit rate on hypotheses. Out of 110 ideas, 9 worked. And out of those 9, only 7 survived hard validation. Because I am treating target like how real pen testers treat target, so 10% hit rate is good for me. I am not looking target from bounty-hunting mindset but from red-team mindset
Lesson 3: Bug bounty is a numbers game wrapped in a thinking game. Generate many ideas, test them all, validate ruthlessly.
What Actually Finds Bugs (From My Data)
I tracked what worked across 17 targets with findings. Here is the ranking:
Top 5 Bug-Finding Techniques (By Success Rate)
1. Configuration File Extraction (80%+ success)
On 8 out of 10 targets I tested, probing /environment.json, /config.json, or /appsettings.json revealed something useful. On one target, this single file exposed Azure AD credentials that enabled a complete account takeover vector against any employee.
Always check: /environment.json, /env.json, /config.json, /appsettings.json, /appsettings.Development.json
2. Source Map Analysis (60%+ success)
When developers forget to remove .js.map files from production, you get the full source code. I found:
- OAuth client IDs and secrets
- Internal service URLs
- Sentry DSN keys (20+ on one target)
- Git commit SHAs that revealed deployment details
3. CSP Header Mining (50%+ success)
Content-Security-Policy headers are a goldmine. Developers add their internal/partner domains to CSP connect-src and script-src directives. I discovered a secondary host serving PII data purely from parsing a CSP header on the main website.
Always read: Every Content-Security-Policy header on every response.
4. Assumption Inversion (40%+ success in ghost-hunting)
This is my favourite technique. Take something that works one way and ask “what if I do the opposite?”
Real example: A Fortinet IPS was blocking requests to a Telerik handler using ?type=rau. I tried ?Type=rau (capital T). The IPS rule was case-sensitive. The application was not. Bypass confirmed.
Another example: Azure AD was supposed to only accept registered redirect URIs. I tried redirect_uri=https://evil.com. No error. The login page rendered with my evil URL embedded in the authentication flow. Authorization code theft - High severity.
5. Version Archaeology (30%+ success)
If app-test.company.com exists, try app.company.com, app-dev.company.com, app-staging.company.com. Different environments often have different security configurations. I found a PRODUCTION environment with the same vulnerability as the TEST environment - simply by changing the subdomain.
What Does NOT Work (Save Your Time)
- Running Nuclei/Nikto and submitting raw output - instant rejection
- Subdomain takeover on CNAME that is not dangling - check with
digfirst - CORS on public APIs that do not use cookie-based auth - informative at best
- “I found an API key” without proving what it can access - always test the scope
- Version disclosure alone - “Server: Apache 2.4.9” is not a vulnerability
The Art of Chaining (Where Real Impact Lives)
My most impactful findings were not single bugs. They were chains.
Chain Example 1: Config File to Account Takeover
- Step 1: Found
/environment.jsonon a test environment - exposed Azure AD client ID and tenant ID (no auth required) - Step 2: Used the client ID to initiate an OAuth device code flow - Azure accepted it
- Step 3: Discovered the same client ID accepts ANY redirect URI - login page renders with attacker URL
- Step 4: Combined: attacker sends employee a legitimate-looking Microsoft login URL, employee authenticates, authorization code goes to attacker’s server
- Impact: Full account takeover of any employee in the organization
Single findings: Medium + Low. Chained: High/Critical.
Chain Example 2: SSRF to Mass Credential Exposure
- Step 1: Found SSRF via a CAPTCHA audio proxy endpoint
- Step 2: Used SSRF to reach an internal Sentry error monitoring instance
- Step 3: Sentry had hardcoded DSN keys - extracted 20+ production monitoring endpoints
- Step 4: Each endpoint leaked internal service URLs, Git SHAs, and deployment metadata
- Impact: Complete mapping of internal infrastructure + credential exposure
Lesson 4: Every finding is a node in a graph. Always ask “what does this enable next?” A Medium IDOR + a Low info disclosure + an SSRF = Critical account takeover.
The Methodology That Changed Everything
I used to hunt randomly. Open Burp, click around, run tools. Hit rate: maybe 5%.
Now I follow a structured process. Here is the simplified version:
Step 1: Understand Before You Touch (30% of time)
- OSINT: Who works there? What tech do they use? Any leaked credentials?
- Recon: Subdomains, live hosts, ports, certificates
- Goal: Build a mental model of the target BEFORE sending a single request
Step 2: Map Everything (20% of time)
- Visit every live host on every port
- Extract JS bundles, config files, API specs
- Read CSP headers, CORS configs, error messages
- Goal: Know every endpoint, parameter, and technology
Step 3: Generate Hypotheses (10% of time)
Wait - what is a hypothesis? Think of it like this. When a doctor sees you coughing, they do not randomly prescribe 50 medicines. They think: “Maybe it is a cold. Maybe it is allergies. Maybe it is something serious.” Each “maybe” is a hypothesis. They test one by one - check temperature, listen to lungs, do a blood test - until they find the real cause.
Bug bounty hunting works the same way. After I map an application, I do not randomly throw payloads at it. I look at what I discovered and form specific, testable guesses. For example: I see an API endpoint that takes a user ID parameter. My hypothesis: “If I change this user ID to someone else’s ID, will the API return their data instead of mine?” That is one testable idea. I see an endpoint returning 401 Unauthorized. My hypothesis: “What if I change the HTTP method from GET to POST - will it bypass the auth check?” Another testable idea. I see an Azure AD client ID exposed in a config file. My hypothesis: “Does this client ID accept any redirect URI, or only the registered ones?” One more testable idea.
Each hypothesis is ONE specific question with a YES/NO answer. I write them all down in a table - the hypothesis, what I am testing, what auth level is needed, and the priority. Then I test them one by one. On a serious target, I generate 100+ hypotheses. Most will be “no” (falsified). But the 5-10 that are “yes” - those are your findings.
The power of this approach: You never miss anything because every observation becomes a question. You never waste time because each test has a specific goal. And when you submit your report, you can say “I tested 110 hypotheses, 9 confirmed” - that tells the triager you were thorough, not lucky.
- For every data point discovered, generate at least one testable idea
- “This endpoint has a user ID parameter → test IDOR with other IDs”
- “This API has no auth → test if write operations work”
- Goal: Convert observations into testable questions
Step 4: Test Systematically (30% of time)
- Test unauthenticated hypotheses first (highest value)
- Minimum depth: 3-5 requests per hypothesis before ruling it out
- Log everything - failures prove thoroughness
- Goal: Confirm or falsify every hypothesis
Step 5: Chain and Maximize (10% of time)
- Connect findings to other findings
- Ask: can I go deeper? Wider? More sensitive data?
- Goal: Maximize the proven impact of every finding
The Key Insight
I generate 500+ hypotheses per serious engagement. About 90 confirm. About 70 survive validation. The remaining 430+ are documented failures - and they are just as valuable because they prove I tested everything.
Report Writing: What Gets Triaged vs What Gets Closed
From my experience submitting 50+ reports, here is what separates a triaged report from an informative/NMI closure:
What Gets Triaged (Do This)
Lead with the impact, not the technique
- Bad: “I found CORS misconfiguration on api.example.com”
- Good: “An attacker can steal any user’s session data from api.example.com via a malicious website”
Show the full PoC with actual responses
- Include the exact curl command
- Include the actual HTTP response (not “it returned sensitive data”)
- Show the specific data that proves the impact
Address “so what?” before the triager asks it
- “This exposes 30M+ user records including email addresses and phone numbers”
- Not: “This endpoint returns user data”
Be honest about limitations
- “Full exploitation requires the victim to click a link and authenticate”
- Not: “An attacker gains full access” (when it actually needs user interaction)
What Gets Closed (Do Not Do This)
- Theoretical impact without proof - “An attacker COULD steal…” without a working PoC
- Scanner output with no analysis - copy-pasting Nuclei/Burp results
- Severity inflation - claiming Critical when the real impact is Medium
- Missing preconditions - not mentioning that the attack needs XSS/phishing/MitM
- Duplicate claims on intended behavior - “CORS allows all origins” on a public API that uses token auth (not cookies)
The XYZ Company Example
When I reported the entire Hypothesis table to XYZ Company, the founder responded:
“Thanks for flagging this, and for the hypothesis table as well. That’s a really helpful resource.”
They paid $500 and said the hypothesis table (my list of what I tested and what I did not test) was valuable to them. The methodology itself was part of the deliverable.
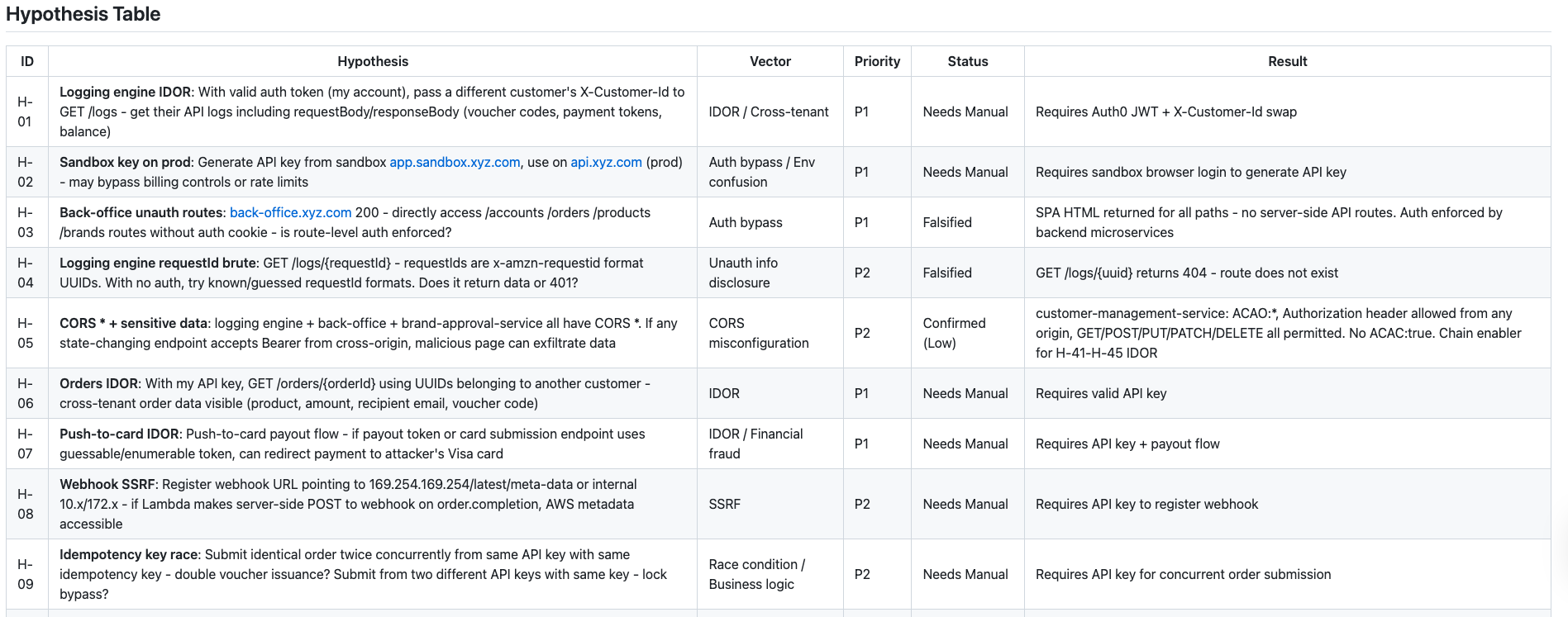
The Mindset: What Nobody Tells You
1. It Is a Race - But Consistency Wins
Bug bounty IS competitive. You WILL get duplicates. Some bugs are so common that many hunters find them around the same time - the first person to report it gets the bounty, and everyone else gets “duplicate” or “informative”. That stings.
But here is the thing: the person who reported was probably consistent. They probably hunted that target every week. Consistency beats bursts of effort every single time.
2. Rejections Are Part of the Game
You will get rejections. Sometimes for valid reasons, sometimes not. Do not let it discourage you. Every rejection is a learning opportunity. Ask for feedback if possible. Understand why it was rejected and use that knowledge to improve your future reports. I have had my reports rejected for various reasons, including: scope issues, impact not being significant enough, or sometimes the program decides a specific finding is not a security issue even if it is technically a vulnerability. This is part of the game.
3. Process Matters More Than Tools
I have seen beginners spend weeks setting up tool chains. Fancy recon pipelines, automated scanners, dashboard after dashboard.
The bugs I found? Most came from:
- Reading JavaScript source code
- Sending manual BurpSuite requests via Repeater
- Thinking “what if this parameter accepts negative numbers?”
- Asking “what happens if I remove the auth header?”
Tools help with discovery. Thinking finds bugs.
4. Some Engagements Turn Into Something Bigger
My xyz.com disclosure in 2026 turned into a relationship for me to become their regular pentester for 6 months. My abc.com (not public yet) submission turned into a private Discord community invite. My structured reporting to startups turned into private pentest assignments.
Bug bounty is not just a job. It is a portfolio that opens doors.
5. The Best Bugs Come from Understanding the Business
My highest-impact findings came from understanding what the application DOES, not just how it is built.
- Understanding that a pump selection ERP system should NOT have open registration → found open registration on production system (High)
- Understanding that OAuth redirect_uri should be validated → found open redirect in Azure AD app (High)
- Understanding that a CAPTCHA proxy might reach internal services → found SSRF to internal Sentry (Critical chain)
Technical skills find Low/Medium bugs. Business understanding finds High/Critical bugs.
Finding Classes That Paid
| Vulnerability Class | Count | Avg Severity | Paid? |
|---|---|---|---|
| Config/Secret Exposure | 4 | High | Yes |
| IDOR/BOLA | 5 | High | Yes |
| SSRF | 4 | High-Critical | Yes |
| Auth Bypass/Missing Auth | 4 | High | Yes |
| CORS Misconfiguration | 1 | Medium | Sometimes |
| Injection (SQLi/NoSQLi/SSTI) | 3 | High-Critical | Yes |
| Business Logic | 3 | Medium-High | Yes |
| Open Redirect/OAuth | 2 | Medium-High | Yes |
| Info Disclosure | 9 | Low | Rarely |
| GraphQL Issues | 4 | Medium-High | Yes |
| Smart Contract Bugs | 1 | High | Yes |
Time Investment vs Returns
| Phase | % of Time | Findings Found |
|---|---|---|
| OSINT + Recon | 30% | Enables everything, 0 direct findings |
| Surface Mapping | 20% | 15% of findings (config files, exposed endpoints) |
| Hypothesis Testing | 30% | 70% of findings (the bulk of work) |
| Chain + Ghost Hunt | 15% | 10% of findings (but highest severity) |
| Reporting | 5% | 5% findings upgraded via better PoC |
The Golden Rule
Submit ONE well-researched, fully-proven finding rather than TEN scanner-output reports. Quality over quantity. Every time.
Final Thoughts
Bug bounty is hard. The stats prove it - I found zero bugs on more than half my targets. I got duplicated. I got rejected. I got reports closed as informative.
But I also got $$$$ in a single payout. I got private pentest invitations. I got thanked by CTOs of startups. I got offered free software licenses. I built a methodology that consistently finds real bugs on real targets.
The difference between someone who quits after their first duplicate and someone who earns consistent bounties is NOT talent. It is:
- Process - having a systematic approach, not random clicking
- Patience - accepting that most hypotheses will be falsified
- Persistence - moving to the next target when one does not pay off
- Learning - every engagement teaches something for the next one
Every duplicate I received proved my methodology works - I was just slower. Every rejection taught me what programs actually care about. Every informational closure taught me the difference between “interesting observation” and “proven security impact.”
Start today. Pick a target. Follow a process. Accept the failures. Learn from them. The bugs are there. The bounties are there. You just have to be consistent enough to find them.
Written from real engagement data across 45+ targets, 120+ findings, and 500+ hypotheses. No theory - just what actually happened.
All company names have been sanitised where required. Vulnerability details are described at a high level to protect ongoing programs.